When One Broken Service Threatens Your Release
You are a QA owning the Checkout service in a large microservices setup. Think it at a travel or e-commerce scale. Here, the Checkout talks to 15 or more downstream services on every run: Payments, Inventory, Pricing, Fraud, Notifications, and a few more you don’t even remember until they fail.
Two days before release, one service goes rogue.
Fraud is unstable in the staging. Random timeouts. Occasional 500s. Schema changes without notice. About 40% of your automation suite is red, and every failure points to Fraud. The Checkout code itself has not changed and manual checks look clean.
Now you are stuck in a very real situation:
- If you mock everything, you lose integration confidence.
- If you wait for the Fraud team, the release slips. If you rerun tests and hope for green, you are gambling.
That's dilemma for a QA team. This post talks through a testing setup that real QA teams use in this exact situation. No theory. No academic answers. A practical solution that keeps your pipeline stable without lying to you.
Why the usual answers fail in practice
On the receiving end of the software development team, a QA, you would have probably heard these suggestions already.
- “Mock all dependencies.” That hides real issues like contract drift, auth headers, retries, and timeouts.
- “Just run tests when Fraud is stable.” That assumes other teams work on your release timeline.
- “Exclude Fraud-dependent tests.” That slowly turns your suite into a false sense of safety.
The problem is not mocking. The problem is mocking blindly.
What you actually need is control. Control over when a dependency is real and when it is to be simulated.
The core idea: Proxy first, mock only when needed
Instead of deciding upfront that a service is mocked or real, you put a proxy in between.
Every downstream service is accessed through an HTTP proxy layer. That proxy does two things:
- Forwards traffic to the real service by default.
- Can switch to mocked responses selectively, without code changes.
This gives you a simple rule: If a dependency behaves, keep it real. If it breaks your suite, isolate it temporarily.
Beeceptor fits naturally into this role because it supports HTTP proxying and mocking in the same endpoint.
How this looks in a real QA setup
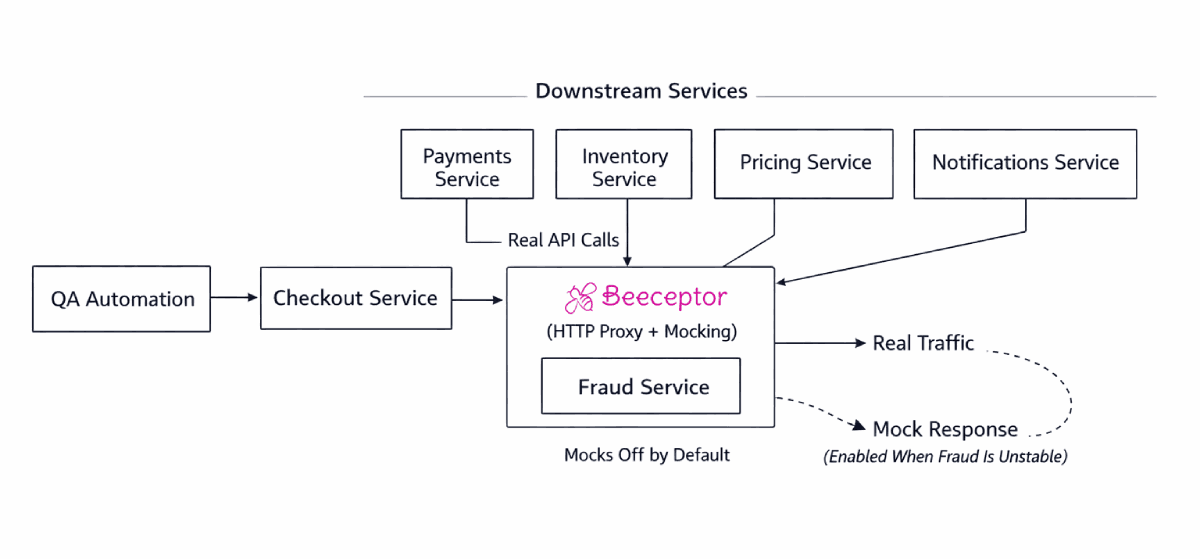
Step 1: Route each dependency through a proxy endpoint
Instead of Checkout calling Fraud directly, it calls:
https://fraud.proxy.beeceptor.com
Behind the scenes, Beeceptor forwards requests to the real Fraud service. At this point, nothing is mocked. Your tests are still full integration tests.
Step 2: Record real traffic during healthy runs
When Fraud is behaving, you let traffic flow through Beeceptor and observe real requests and responses.
This gives you:
- Real payloads
- Real headers
- Real edge cases
- Real response timing
From this, you create mock rules that represent realistic Fraud behavior, not guesswork. Now you aren't inventing mocks. You are capturing reality.
Step 3: Keep mocks turned off by default
This step is important. In normal runs, Proxy is on
- Mock rules exist
- Mock behavior is disabled
Your suite continues to catch real integration bugs. Auth issues. Schema changes. Unexpected fields. All of it.
Step 4: Selectively enable mocks when a service breaks
When Fraud service goes down again, you don’t touch Checkout code. You don’t skip tests. You don’t argue with other teams anymore. You flip a switch at Beeceptor.
Only Fraud mocks are enabled. All other services still hit real environments.
Now your Checkout tests run against real payments and real inventory. The simulated Fraud service that behaves predictably. Your suit stabilizes instantly.
Step 5: Use stateful mocks to keep flows realistic
Fraud checks are rarely single-call APIs. There is usually context involved: order IDs, risk scores, retry attempts, or progressive decisions.
Beeceptor supports stateful mocks using counters, data stores, and lists. That means your Fraud mock can behave like this:
- First request returns “under review”
- Second request returns “approved”
- Third request returns “blocked”
You can manage these behaviros from the Beeceptor UI. No test code changes, no custom servers. Just configuration.
This matters because Checkout flows often depend on sequences, not static responses.
What you gain as a QA
This setup does three important things for you.
- First, your test suite becomes stable even when one dependency is unstable.
- Second, you don’t lose integration coverage. Most services stay real, most of the time.
- Third, you stop being blocked by external teams while still testing realistically.
That is the difference between testing and shipping.
Mental Shift
A quick mental shift that helps
If you are currently thinking in terms of: “Are we mocking or not mocking?”
Switch to:
“Which dependencies are allowed to break my build today?”
A mature QA organization does not let third-party instability decide release speed.
Wrap up
In this complex enginering setup, instability is normal, and accepted by mostly. What separates strong QA teams is how they isolate that instability without hiding real issues.
Using an HTTP proxy plus selective mocking gives you that control. Beeceptor provides this combination out of the box, with support for traffic proxying, one-click mock toggling, and stateful behavior without writing code.
If you are testing a service with many dependencies and tight release timelines, this setup is worth trying. Once you run a green suite during a dependency outage, it is hard to go back.
Next time a downstream service is on fire, your release does not have to be.